ICTSC9のバックボーン解説 – 監視編
監視
はじめに
こんにちは、今回運営として主に監視の仕事をしていました源波です。
今回は、前回大会の電源トラブルからの反省を元に監視体制を強化しています。結果的には前回と同じ電源周りのトラブルで大会を一時中断せざるを得ない状況に陥りましたが、監視のおかげで原因の切り分けがスムーズに進み、早期の復旧につながったのではないかと考えています。
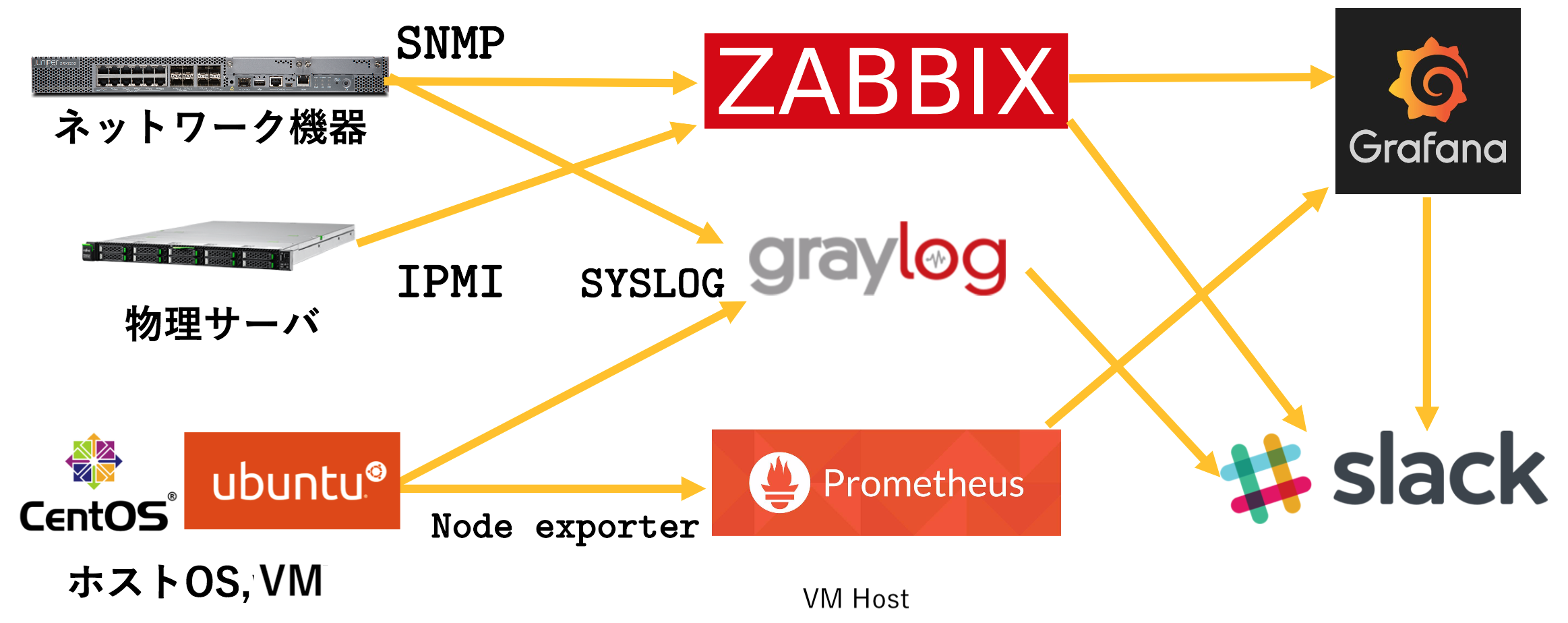
今大会では、大まかに上の図のような監視体制を取りました。
Grafana
Grafanaでは、PrometheusやZabbixで取得したデータをグラフ化して、値を視覚から感じ取ることができました。Grafanaの監視画面は以下のようになっていました。



監視項目については、それぞれの節で説明します。
Prometheus
前回大会までは監視ツールとしてすべてZabbixを使用していましたが、今大会からは部分的にPrometheusに移行しています。Prometheusでは、Node Exporterを用いて物理サーバーのホストOSやVMのゲストOSのステータス監視を行っていました。具体的には以下の値を取得し、可視化していました。
- CPU使用率
- メモリ使用率
- ディスク容量
- コンテストサイトのレスポンスタイム
前述した電源トラブルの際には、6台のIBM X3750 m4のうち、同系統の電源に接続していた3台のCPU使用率監視が途切れ、電源系統の異常に気づくことができました。
また、ディスク容量の監視によって、コンテストサイトのDBバックアップが正常に取れていないというトラブルに即座に気づくことができました。
Zabbix
Zabbixでは、Prometheusに移行することができなかったネットワーク機器と物理サーバーの各種センサ値の監視を行いました。また、先程の図にはありませんでしたが、VMゲストのPing,SSH監視、バックボーンのネットワーク機器、各チームに提供したネットワーク機器のPing,Telnet監視も行っていました。今回のバックボーン構成では、Home NOC Operators Group様より提供頂いたBGPフルルートを、Juniper様よりお借りしたSRX1500で受けていたので、SNMPでその経路数を取得するということも行いました。具体的には以下の値を取得していました。
- 各ネットワーク機器のトラフィック量
- 各ネットワーク機器のPing,Telenet疎通性
- 各VMのPing,SSH疎通性
- BGPルート数
- 物理サーバーの消費電力
- 物理サーバー内の温度
競技中は、各ネットワーク機器のトラフィックをスクリーンに移しつつ眺めていました。また、トラフィックの監視を行うことによって、「rs232c使ったことあります?」問題のAlaxalaのL2SWから流れる大量のトラフィックがバックボーン機材まで影響を与えているというトラブルを発見することができました。
2日目の昼間には、上流ISPの障害がありましたが、これもBGPのルート数が一気に5000経路ほどなくなっているのが、グラフから伝わってくるという面白い体験ができました。
graylog
graylogでは、ネットワーク機器やDNSサーバーのsyslog収集といったテキスト処理を行いました。これらは、競技中はあまり監視は行わなかったものの、競技終了後に眺めようということで記録をしてあります。
まとめ
今回監視サーバー群は、問題VMや他ライフサーバー群と同じく OpenStack上に構築してありました。電源トラブルが拡大した際には、監視サーバー群からの応答もなくなってしまうということもありました。たまたま最初に落ちたサーバーに監視サーバー群が乗っていなかったため早期の原因究明につながりましたが、次回は今回の失敗をもとに監視サーバー群は外部に設置するなどの対策を行いたいと考えています。